Apache Kafka – Topics and Partition with offset
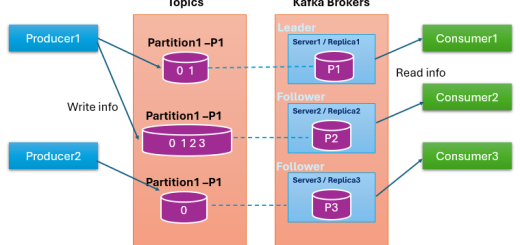
In Apache Kafka, topics are the main channels through which messages are sent, and topics can be divided into partitions for scalability and parallelism. Each message in a partition has a unique offset that acts as a position indicator for that message.
Let’s break down how topics, partitions, and offsets work in Kafka with an example and see how you can use them in your Kafka application.
Key Concepts
- Topic:
- A Kafka topic is a stream of records or messages. Producers send messages to topics, and consumers read messages from topics.
- Kafka topics are logically categorized message channels.
- Partition:
- Kafka topics are divided into partitions. Each partition is a separate log file where messages are written in a sequential and immutable order.
- Partitions allow Kafka to scale horizontally by distributing partitions across multiple brokers.
- Offset:
- Each message within a partition is identified by a unique offset, which is a sequential number that represents the message’s position within the partition.
- Offsets are maintained by Kafka to allow consumers to keep track of which messages have been consumed.
- Consumers use offsets to read the next message in the partition and can even re-read messages by adjusting the offset (rewind or skip).
Example: Kafka Topics, Partitions, and Offsets
Let’s create a simple Kafka application that demonstrates topics, partitions, and offsets.
Step 1: Kafka Setup
Ensure you have Apache Kafka installed and running. You should have Kafka brokers running either in Zookeeper mode or KRaft mode (without Zookeeper).
For this example, we will assume you have a running Kafka cluster on localhost:9092.
Step 2: Create Kafka Topic with Partitions
To create a Kafka topic with multiple partitions, you can use the following command:
bin/kafka-topics.sh --create --topic insurance_policies \
--bootstrap-server localhost:9092 \
--partitions 3 --replication-factor 1This command creates a topic named insurance_policies with 3 partitions. Each partition will store a separate stream of messages.
- 3 partitions: This will allow the topic to handle data in parallel across 3 brokers (or partitions, in a single-broker case).
- Replication-factor 1: This means only one copy of the partition will be stored on one broker. In a production setup, you’d typically want this value to be greater than 1.
Step 3: Produce Messages to Kafka Topic
Let’s write a simple Kafka producer in Java that sends insurance policy messages to the insurance_policies topic.
Producer Code Example
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class InsuranceProducer {
public static void main(String[] args) {
String bootstrapServers = "localhost:9092";
String topic = "insurance_policies";
// Set properties for the producer
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// Create Kafka producer
KafkaProducer producer = new KafkaProducer<>(properties);
// Sample insurance policy data (in JSON format)
String[] policies = {
"{\"policyId\":\"P12345\", \"customer\":\"John Doe\", \"coverage\":\"Health\", \"amount\":50000}",
"{\"policyId\":\"P12346\", \"customer\":\"Jane Smith\", \"coverage\":\"Life\", \"amount\":100000}",
"{\"policyId\":\"P12347\", \"customer\":\"Mike Johnson\", \"coverage\":\"Car\", \"amount\":20000}"
};
// Send data to insurance_policies topic
try {
for (String policy : policies) {
// Send each message to Kafka (default partition assignment)
ProducerRecord record = new ProducerRecord<>(topic, null, policy);
producer.send(record);
System.out.println("Sent: " + policy);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}This producer sends three insurance policy messages to the insurance_policies topic. Kafka will automatically decide which partition to send each message based on the key (if provided) or round-robin partitioning.
To run the producer:
javac InsuranceProducer.java
java InsuranceProducerStep 4: Kafka Consumer to Read Messages with Offsets
Now, let’s write a Kafka consumer that reads messages from the insurance_policies topic and processes them.
Consumer Code Example
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
import java.util.Collections;
public class InsuranceConsumer {
public static void main(String[] args) {
String bootstrapServers = "localhost:9092";
String groupId = "insurance_group";
String topic = "insurance_policies";
// Set properties for the consumer
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Create Kafka consumer
KafkaConsumer consumer = new KafkaConsumer<>(properties);
// Subscribe to the insurance_policies topic
consumer.subscribe(Collections.singletonList(topic));
// Poll for new messages and process them
try {
while (true) {
var records = consumer.poll(1000); // Poll every 1 second
for (ConsumerRecord record : records) {
System.out.println("Consumed: " + record.value() + ", Offset: " + record.offset());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}This consumer subscribes to the insurance_policies topic and processes each message it receives. It prints out both the message and its offset.
To run the consumer:
javac InsuranceConsumer.java
java InsuranceConsumerThe consumer will output something like this:
Consumed: {"policyId":"P12345", "customer":"John Doe", "coverage":"Health", "amount":50000}, Offset: 0
Consumed: {"policyId":"P12346", "customer":"Jane Smith", "coverage":"Life", "amount":100000}, Offset: 1
Consumed: {"policyId":"P12347", "customer":"Mike Johnson", "coverage":"Car", "amount":20000}, Offset: 2
- The offset value corresponds to the message’s position in the partition.
- Offsets are unique per partition, so if the topic has multiple partitions, each partition will maintain its own set of offsets.
Step 5: Consumer Offset Management
Kafka manages consumer offsets automatically, but you can also control offset management manually. By default, Kafka consumers commit offsets automatically at intervals, but you can disable this behavior and commit offsets manually using the following property in the consumer configuration:
enable.auto.commit=falseIf you manage offsets manually, you can use the following code to commit offsets manually:
consumer.commitSync();Conclusion
In this example, we demonstrated how Kafka topics, partitions, and offsets work together:
- Topics are logical channels for messages.
- Partitions allow Kafka to scale horizontally, with each partition storing a separate sequence of messages.
- Offsets are used by consumers to track their progress within a partition.
With these concepts, you can build scalable, fault-tolerant, and distributed systems that process large volumes of data in real time.

Recent Comments