Apache Kafka – Introduction
Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications. It was originally developed by LinkedIn and is now an open-source project under the Apache Software Foundation. Kafka is designed to handle large volumes of data in a fault-tolerant, scalable, and high-throughput manner. It allows applications to publish and subscribe to streams of records in real-time.
Apache Kafka is a free and open tool we use for streaming events. It helps us build real-time data pipelines and streaming apps. Kafka allows organizations to publish, subscribe to, store, and process streams of records in a way that is safe from errors.
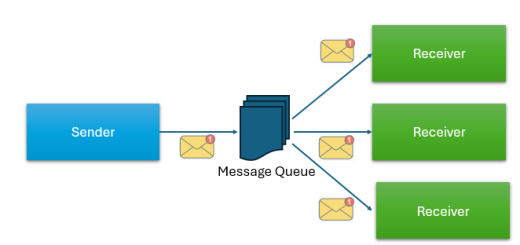
Kafka works with a special system called a distributed commit log. This system helps us manage a lot of data quickly and with little delay. It uses producers and consumers. Producers send data to topics, and consumers read from those topics.
This setup helps us scale and keep our data safe. It also gives us a strong order of messages. That is why Kafka is a great choice for apps that need reliable data streaming. Examples include log aggregation, data integration, and real-time analytics.
Key features of Kafka:
- Publish-Subscribe Messaging: Kafka allows producers to send messages (data) to topics, and consumers can subscribe to those topics to process the data.
- Scalability: Kafka can handle large-scale data streams, supporting high-throughput messaging with low latency. It scales horizontally by adding more brokers to the cluster.
- Fault Tolerance: Kafka ensures data durability by replicating messages across multiple brokers in the cluster. Even if a broker fails, the data remains available.
- Durability: Kafka messages are stored on disk, making it suitable for storing large amounts of data for future processing or analysis.
- Stream Processing: Kafka can be integrated with stream processing frameworks to process data in real-time, allowing applications to react to events as they happen.
Other similar technologies to Kafka:
- RabbitMQ: A message broker that supports multiple messaging protocols. Unlike Kafka, RabbitMQ uses a traditional queue-based model and is often used for task queues and managing asynchronous workloads.
- Apache Pulsar: A distributed messaging and event streaming platform. Like Kafka, Pulsar supports multi-tenant environments, strong message guarantees, and scalability, but it also supports features like topic-level message retention and more granular message acknowledgement.
- Amazon Kinesis: A managed service provided by AWS for real-time data streaming. It allows users to ingest, process, and analyze large streams of data in real-time, similar to Kafka, but fully managed by AWS.
- Apache ActiveMQ: A message broker that provides enterprise messaging capabilities. It supports a wide range of messaging protocols (like AMQP, MQTT, OpenWire, and STOMP) and is used for real-time communication between applications.
- NATS: A lightweight, high-performance messaging system that focuses on simplicity and speed. NATS can be used for event-driven applications, microservices, and IoT systems.
- Redis Streams: A data structure in Redis for managing streams of data in a way similar to Kafka. It provides low-latency, in-memory message storage, ideal for real-time applications that need high-speed access to data.
- Google Cloud Pub/Sub: A messaging service by Google Cloud for building event-driven systems. Like Kafka, it provides scalable, real-time messaging but as a fully managed service in the cloud.
Each of these technologies has its strengths and weaknesses, and the choice of which to use depends on the specific use case, such as scalability needs, messaging patterns (e.g., publish-subscribe or queue-based), or the specific features required by the application.

Recent Comments